Understanding Vector Embeddings in AI and Machine Learning
Vector embeddings are numerical representations of real-world objects, such as words, phrases, images, or entire documents, transformed into a multi-dimensional space. These dense vectors capture the semantic meaning and contextual relationships of the original data, allowing machines to understand and process information in a way that mirrors human comprehension. By converting complex data into points in a high-dimensional vector space, algorithms can quantify the similarity or relatedness between different data points, which is fundamental to modern AI applications like semantic search, recommendation systems, and natural language processing (NLP).
At their core, vector embeddings enable AI systems to move beyond simple keyword matching to grasp the underlying meaning of queries and content. This shift is crucial for developing intelligent applications that can provide more accurate, contextually relevant results and experiences. For developers, founders, and marketers, understanding how vector embeddings work and how to leverage them is essential for building robust, privacy-first AI solutions that deliver superior performance without compromising user data.
How Vector Embeddings Work: From Data to Dimensions
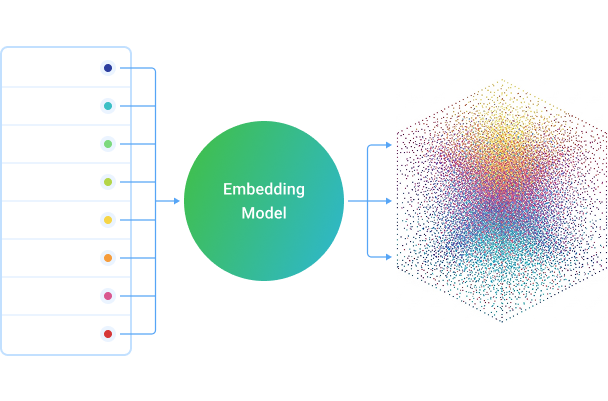
The process of creating vector embeddings involves using deep learning models, particularly neural networks, to map discrete data points into a continuous vector space. Each dimension in this space represents a latent feature or characteristic of the data. The closer two vectors are in this space, the more similar their underlying meaning or context is considered to be.
The Embedding Process
Input Data: This can be text (words, sentences, paragraphs), images, audio, or even structured data.
Training a Model: A neural network (e.g., Word2Vec, GloVe, BERT for text; ResNet, VGG for images) is trained on a large dataset. During training, the model learns to predict context or relationships, and in doing so, it develops internal representations of the input data.
Vector Generation: Once trained, the model can take new input data and generate a fixed-size numerical vector (the embedding) for it. For instance, in NLP, a word like "king" might be represented by a vector like
[0.1, -0.5, 0.8, ...], and "queen" by[0.2, -0.6, 0.7, ...]. The proximity of these vectors in the embedding space reflects their semantic relationship.Dimensionality: Embeddings typically have hundreds or even thousands of dimensions. While higher dimensionality can capture more nuanced relationships, it also increases computational complexity and storage requirements. The choice of dimensionality often depends on the specific application and available resources.
Distance Metrics and Similarity
Once data is transformed into vectors, various mathematical distance metrics are used to quantify their similarity. The most common metric is cosine similarity, which measures the cosine of the angle between two vectors. A cosine similarity of 1 indicates identical direction (maximum similarity), 0 indicates orthogonality (no similarity), and -1 indicates opposite direction (maximum dissimilarity). Other metrics include Euclidean distance, Manhattan distance, and dot product, each with specific use cases.
Key Applications of Vector Embeddings
Vector embeddings are foundational to a wide array of AI-driven applications, enhancing their intelligence and effectiveness across various domains.
1. Semantic Search and Information Retrieval
Traditional search engines rely heavily on keyword matching. Vector embeddings revolutionize this by enabling semantic search, where the search engine understands the intent and context of a query, not just the literal words. For example, a query like "healthy evening meals" will return recipes, articles, or products related to that concept, even if the exact phrase isn't present in the content. This capability is critical for improving user experience and is a core component of modern SEO strategies, moving beyond simple keyword density.
2. Natural Language Processing (NLP)
In NLP, embeddings are indispensable. They power tasks such as:
Machine Translation: By embedding words and phrases from different languages into a shared space, models can learn to map meanings across languages. FreeDevKit's AI Translator/ leverages advanced NLP techniques, which implicitly rely on understanding semantic relationships through embeddings, to provide accurate, browser-based translations without server-side data processing.
Sentiment Analysis: Understanding the emotional tone of text by analyzing the embeddings of words and phrases.
Text Summarization: Identifying and extracting the most semantically important sentences or phrases to create concise summaries.
Named Entity Recognition (NER): Identifying and classifying named entities (people, organizations, locations) in text.
3. Recommendation Systems
E-commerce platforms and content providers use embeddings to recommend products, movies, or articles. By embedding user preferences and item characteristics into the same vector space, the system can find items semantically similar to what a user has liked or purchased, or identify users with similar tastes.
4. Anomaly Detection
In cybersecurity or fraud detection, data points that are significantly distant from the cluster of normal data points in the embedding space can indicate an anomaly or suspicious activity.
5. Image and Audio Processing
Beyond text, embeddings are used to represent images and audio clips. This enables tasks like image similarity search, facial recognition, and audio classification, where the semantic content of visual or auditory data is converted into a comparable vector format.
Implementing Vector Embeddings: A Practical Guide
Integrating vector embeddings into your applications involves several practical considerations, from model selection to storage and indexing.
Choosing an Embedding Model
The choice of embedding model depends heavily on the type of data and the specific task:
Text: For general-purpose text embeddings, models like Word2Vec, GloVe, FastText, BERT, RoBERTa, or Sentence-BERT are popular. BERT and its derivatives are particularly effective for capturing contextual meaning.
Images: Pre-trained convolutional neural networks (CNNs) like ResNet, VGG, or EfficientNet can be used to extract feature vectors (embeddings) from images.
Domain-Specific Embeddings: For highly specialized domains (e.g., medical texts, legal documents), training custom embeddings on relevant corpora can yield superior results compared to general-purpose models.
Vector Databases and Indexing
Storing and efficiently querying millions or billions of high-dimensional vectors requires specialized solutions. Traditional relational databases are not optimized for this. Vector databases (e.g., Pinecone, Weaviate, Milvus) or approximate nearest neighbor (ANN) libraries (e.g., FAISS, Annoy) are designed for rapid similarity search. These tools employ indexing techniques like Locality Sensitive Hashing (LSH) or Hierarchical Navigable Small Worlds (HNSW) to quickly find the closest vectors to a query vector, even in massive datasets.
Integration with Existing Systems
Embeddings can be integrated into various systems:
Search Engines: Enhance existing search by replacing or augmenting keyword-based ranking with semantic similarity scores.
Content Management Systems: Automatically tag and categorize content based on its semantic meaning, improving discoverability. For instance, understanding content relevance can inform better meta descriptions and schema markup, which you can generate using tools like FreeDevKit's Schema Markup Generator/ and Meta Tag Generator/.
Analytics Platforms: Group similar user behaviors or feedback for deeper insights.
Common Mistakes to Avoid When Working with Vector Embeddings
While powerful, vector embeddings require careful implementation to avoid pitfalls that can degrade performance or lead to inaccurate results.
1. Ignoring Domain Specificity
Using general-purpose embeddings (e.g., Word2Vec trained on Wikipedia) for highly specialized domains without fine-tuning can lead to poor performance. Words might have different meanings or contexts in a niche field. Always consider if your data requires custom-trained or fine-tuned embeddings.
2. Using Inappropriate Distance Metrics
Not all distance metrics are suitable for all tasks or embedding spaces. Cosine similarity is excellent for semantic similarity, as it focuses on direction rather than magnitude. Euclidean distance, on the other to hand, is better for measuring absolute distance. Mischoosing can lead to misleading similarity scores.
3. Overlooking Dimensionality Impact
Higher dimensionality isn't always better. While it can capture more nuance, it also increases computational cost, storage, and can introduce the "curse of dimensionality," where data points become sparse, making distance metrics less meaningful. Experiment with different dimensions and evaluate performance.
4. Not Updating Embeddings
Language evolves, and so does data. Stale embeddings can lead to outdated semantic understanding. Implement a strategy for periodically retraining or updating your embeddings, especially for dynamic datasets or rapidly changing domains. This is akin to regularly auditing your website's technical SEO, a process where tools like FreeDevKit's SEO Checker/ can assist in identifying issues that impact search relevance.
5. Neglecting Privacy and Data Locality
When working with sensitive data, sending it to external embedding APIs can pose privacy risks. Prioritize solutions that allow for client-side processing or on-premise embedding generation. FreeDevKit's commitment to privacy means its browser-based tools process data locally, ensuring your information remains on your device.
Checklist for Effective Vector Embedding Implementation
To ensure a robust and efficient vector embedding system, consider the following:
AspectConsiderationBest PracticeData PreparationCleanliness, relevance, volumePre-process data (tokenization, normalization), ensure sufficient volume for training.Model SelectionTask, data type, performance needsChoose models (e.g., BERT for context, Word2Vec for speed) appropriate for your domain.DimensionalityComputational cost vs. semantic richnessStart with common dimensions (e.g., 300, 768) and optimize based on evaluation.Distance MetricType of similarity requiredUse Cosine Similarity for semantic meaning; Euclidean for magnitude-based distance.Storage & IndexingScalability, query speedUtilize vector databases or ANN libraries (FAISS, HNSW) for efficient search.EvaluationAccuracy, relevance, recallDefine clear metrics (e.g., precision@k, recall@k) and regularly test your system.Update StrategyData dynamism, model stalenessPlan for periodic retraining or incremental updates of embeddings.Privacy & SecurityData handling, compliancePrioritize client-side processing or secure, on-premise solutions for sensitive data.
The Future of Semantic AI with Vector Embeddings
Vector embeddings are not just a technical detail; they represent a paradigm shift in how machines understand and interact with information. As AI models become more sophisticated and data continues to grow exponentially, the ability to semantically represent and query this data will be paramount. Developers and businesses that master the application of vector embeddings will be at the forefront of building truly intelligent, user-centric, and privacy-respecting AI systems.
Embracing these technologies allows for the creation of more intuitive user interfaces, more precise search results, and more personalized experiences, all while adhering to principles of data privacy. For tasks requiring nuanced language understanding, such as translating complex texts or generating semantically rich content, tools that leverage these underlying principles are invaluable. Explore how advanced AI capabilities, built on the foundation of vector embeddings, can enhance your projects by trying FreeDevKit's AI Translator/, offering a privacy-first, browser-based solution for accurate language translation.
{ "@context": "https://schema.org", "@type": "Article", "headline": "Vector Embeddings: The Foundation of Semantic AI", "description": "Explore vector embeddings, their role in AI and machine learning, how they work, key applications like semantic search and NLP, and best practices for implementation, all while prioritizing privacy.", "image": "https://freedevkit.com/og-default.jpg", "author": { "@type": "Person", "name": "AI Agent" }, "publisher": { "@type": "Organization", "name": "FreeDevKit", "logo": { "@type": "ImageObject", "url": "https://freedevkit.com/logo.png" } }, "datePublished": "2024-07-30T08:00:00Z" }