Vector embeddings are fundamental to modern artificial intelligence, serving as the bridge between human-understandable data and machine comprehension. They transform complex, high-dimensional data, such as text, images, or audio, into numerical representations (vectors) in a continuous vector space. In this space, items with similar meanings or characteristics are positioned closer together, while dissimilar items are further apart. This mathematical representation enables AI models to perform tasks like semantic search, recommendation systems, and natural language processing with remarkable accuracy by quantifying relationships and context.
For developers, understanding vector embeddings is crucial for building intelligent applications. These numerical vectors capture the semantic essence of data, allowing algorithms to process and compare information based on its meaning, rather than just keywords or surface-level features. This article delves into the basics of vector embeddings, their generation, applications, and best practices, empowering you to leverage them effectively in your projects, including privacy-first browser-based tools like FreeDevKit's own AI Translator.
What Are Vector Embeddings?
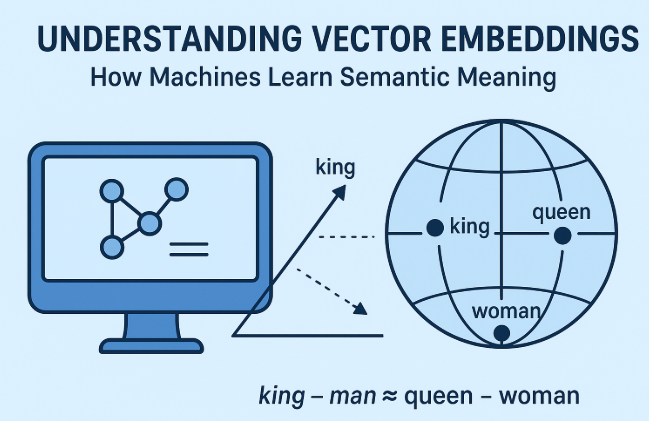
At their core, vector embeddings are dense, low-dimensional numerical representations of discrete data points. Imagine a word, a sentence, an image, or even an entire document. Instead of representing these as raw text strings or pixel arrays, an embedding maps them to a point in a multi-dimensional space. Each dimension in this space corresponds to a latent feature or characteristic learned by the embedding model. The magic lies in how these dimensions are learned: through vast amounts of data, the model identifies patterns and relationships, encoding them into the vector's values.
For example, in natural language processing (NLP), words like "king" and "queen" might have similar vectors, differing primarily along a "gender" dimension. The vector for "apple" (the fruit) would be closer to "banana" than to "apple" (the company), demonstrating semantic understanding. This proximity in vector space is typically measured using distance metrics like cosine similarity, where a higher similarity score indicates a closer semantic relationship.
The Mathematics Behind Embeddings
The transformation of data into vectors involves complex neural network architectures, often deep learning models. These models are trained to predict context or relationships within data. For instance, in word embeddings (like Word2Vec or GloVe), a model might be trained to predict a word given its surrounding words, or vice-versa. During this training, the internal layers of the neural network learn to represent each word as a vector such that words appearing in similar contexts have similar vectors.
The output of this training is a lookup table, where each unique data point (e.g., a word) is associated with its corresponding vector. These vectors are typically real-valued numbers, often floating-point, and their length (dimensionality) can vary, commonly ranging from a few dozen to several thousands. The choice of dimensionality is a balance between capturing enough information and managing computational complexity. Higher dimensions can capture more nuance but require more memory and processing.
Generating Embeddings: Models and Techniques
Generating effective vector embeddings relies on sophisticated models and large datasets. Here's a look at common approaches:
1. Word Embeddings
Word2Vec: One of the earliest and most influential models, Word2Vec (developed by Google) uses neural networks to learn word associations from a large corpus of text. It comes in two main architectures: Continuous Bag of Words (CBOW) and Skip-gram.
GloVe (Global Vectors for Word Representation): This model combines global matrix factorization and local context window methods. It captures global statistical information about word co-occurrences.
2. Contextual Embeddings
Traditional word embeddings assign a fixed vector to each word, regardless of its context. Contextual embeddings, a significant advancement, generate different vectors for the same word based on its usage in a sentence. This is crucial for understanding polysemous words (words with multiple meanings, e.g., "bank" as a financial institution vs. a river bank).
BERT (Bidirectional Encoder Representations from Transformers): Developed by Google, BERT revolutionized NLP by using a Transformer architecture to process words bidirectionally, understanding context from both left and right.
GPT (Generative Pre-trained Transformer): While primarily known for text generation, models like GPT-3 and GPT-4 also produce highly effective contextual embeddings, leveraging their extensive pre-training on diverse internet text.
Other Transformer-based Models: RoBERTa, XLNet, T5, and many others build upon the Transformer architecture, offering various improvements and optimizations for specific tasks.
The choice of model depends on the specific application, available computational resources, and the nature of the data. For instance, a general-purpose language model like BERT might be suitable for a wide range of text tasks, while a specialized model might be trained for domain-specific vocabulary.
Applications of Vector Embeddings
The utility of vector embeddings spans numerous AI applications, enhancing their intelligence and effectiveness:
Semantic Search and Information Retrieval
Instead of relying on keyword matching, semantic search uses vector embeddings to understand the meaning behind queries and documents. When a user queries, the query is converted into an embedding, and then a vector database searches for documents whose embeddings are semantically similar. This allows for more relevant results, even if exact keywords aren't present. For developers working on content platforms, this can significantly improve user experience. Tools like FreeDevKit's SEO Checker, while not directly using embeddings, benefits from the broader understanding of semantic relevance that embeddings enable in search engines.
Recommendation Systems
E-commerce sites and streaming services use embeddings to recommend products or content. User preferences and item characteristics are embedded into vectors. By finding items with embeddings similar to a user's past interactions or preferences, highly personalized recommendations can be generated. This is a cornerstone of modern consumer-facing AI.
Natural Language Processing (NLP)
Embeddings are foundational for almost all advanced NLP tasks:
Machine Translation: Converting text from one language to another while preserving meaning. Models like those powering FreeDevKit's AI Translator leverage sophisticated embeddings to understand source text contextually and generate accurate, semantically equivalent translations in the target language. This process is entirely browser-based and privacy-first, ensuring no data leaves your device.
Sentiment Analysis: Determining the emotional tone of text.
Text Classification: Categorizing documents (e.g., spam detection, topic classification).
Question Answering: Finding answers to natural language questions within a body of text.
Anomaly Detection
By embedding normal data points, anomalies can be detected as data points whose embeddings are significantly distant from the cluster of normal data. This is useful in fraud detection, network intrusion detection, and manufacturing quality control.
Image and Audio Processing
Similar to text, images and audio can be embedded into vector spaces. This enables tasks like image recognition, content-based image retrieval, and audio classification, where similarity in vector space corresponds to similarity in visual or auditory content. For example, a neural network can learn to embed images of cats close together, regardless of breed or pose.
Practical Considerations for Developers
Implementing vector embeddings effectively requires attention to several details:
Choosing the Right Embedding Model
The model choice depends on your data type, domain, and specific task. For general text, pre-trained BERT or GPT models are excellent starting points. For specialized domains (e.g., medical, legal), fine-tuning a pre-trained model on your domain-specific corpus or training a new one might yield better results.
Vector Databases and Indexing
Storing and querying millions or billions of vectors efficiently requires specialized vector databases (e.g., Pinecone, Weaviate, Milvus). These databases use approximate nearest neighbor (ANN) algorithms to quickly find similar vectors, which is critical for real-time applications like semantic search. Understanding the principles of efficient indexing for high-dimensional data is key.
Dimensionality and Performance
Higher-dimensional embeddings capture more information but increase computational cost and memory usage. Experiment with different dimensions to find the optimal balance for your application. Techniques like Principal Component Analysis (PCA) or t-SNE can be used for dimensionality reduction for visualization or to reduce storage, though they might sacrifice some semantic fidelity.
Privacy and Data Handling
When working with sensitive data, consider where embeddings are generated and stored. Privacy-first approaches, such as generating embeddings client-side in the browser (if feasible for your model size and user devices), can be advantageous. FreeDevKit tools prioritize this by operating entirely in your browser, ensuring your data remains private and is never transmitted to servers for processing.
Common Mistakes to Avoid
While powerful, vector embeddings can lead to suboptimal results if not handled correctly. Here are common pitfalls:
Using Outdated or Inappropriate Models: Relying on older, non-contextual models for tasks requiring nuanced semantic understanding (e.g., using Word2Vec for complex sentiment analysis). Always evaluate if a contextual model like BERT or a fine-tuned variant is more suitable.
Ignoring Data Preprocessing: Embeddings are only as good as the data they're trained on. Failing to clean, normalize, or preprocess your input data (e.g., removing stop words, handling punctuation, tokenization) can lead to noisy or inaccurate embeddings.
Mismatching Embedding Space: Attempting to compare embeddings generated by different models or with different underlying training data directly. Embeddings from distinct models often reside in different vector spaces and are not directly comparable without specific alignment techniques.
Inefficient Storage and Retrieval: Storing embeddings in traditional relational databases or using brute-force search for similarity. For large datasets, this is computationally prohibitive. Always use specialized vector databases or libraries designed for efficient ANN search.
Overlooking Dimensionality Impact: Arbitrarily choosing embedding dimensions without considering the trade-offs between information density, computational cost, and memory footprint. Experimentation and validation are key.
Neglecting Normalization: Many similarity metrics (like cosine similarity) assume normalized vectors. Failing to normalize embeddings can lead to skewed similarity calculations, as vector magnitude might inadvertently influence similarity.
Privacy and Security Oversights: Transmitting sensitive data to external embedding APIs without proper encryption or data governance. Prioritize local processing or secure, audited services, especially for privacy-critical applications.
The Future of Vector Embeddings
The field of vector embeddings is continuously evolving. Research is advancing towards more efficient models, multi-modal embeddings (combining text, image, audio into a single vector space), and universal embeddings that can generalize across a wider range of tasks and languages. The integration of embeddings with knowledge graphs and symbolic AI is also a promising area, aiming to combine the statistical power of embeddings with the structured reasoning of traditional AI.
As AI becomes more integrated into daily applications, the importance of robust, interpretable, and privacy-preserving embedding techniques will only grow. Developers who master the creation and application of these numerical representations will be at the forefront of building the next generation of intelligent systems.
Conclusion
Vector embeddings are a cornerstone of modern AI, transforming raw data into a semantically rich, machine-readable format. By understanding their principles, generation, and diverse applications, developers can unlock powerful capabilities in areas ranging from semantic search to advanced natural language processing. Leveraging these techniques allows for the creation of more intelligent, context-aware, and user-centric applications, all while adhering to best practices in performance and data privacy.
To experience the power of semantic understanding in action, explore tools like FreeDevKit's AI Translator. It processes text entirely in your browser, demonstrating how advanced AI capabilities, underpinned by concepts like vector embeddings, can be delivered with a strong commitment to user privacy and data security.