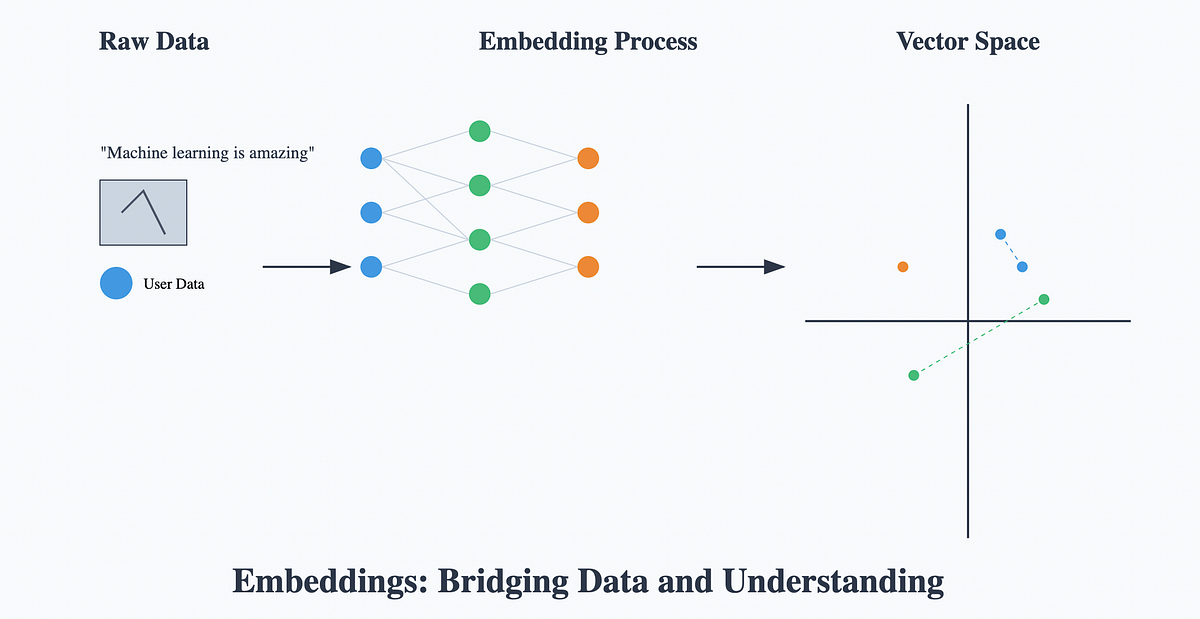
Vector embeddings are a fundamental concept in modern artificial intelligence, transforming complex data like text, images, and audio into numerical vectors. These high-dimensional representations capture semantic relationships, enabling machines to understand context and similarity, which is crucial for tasks like natural language processing, recommendation systems, and AI translation. By converting disparate data types into a unified numerical format, vector embeddings serve as the bedrock for advanced machine learning algorithms to process, analyze, and generate human-like understanding.
At their core, vector embeddings map items from a high-dimensional space (e.g., words in a vocabulary, pixels in an image) to a lower-dimensional continuous vector space. In this new space, items with similar meanings or characteristics are positioned closer together. This geometric representation allows for mathematical operations to infer relationships, making it possible for AI systems to perform tasks that require a nuanced understanding of data, such as identifying synonyms, recommending related products, or providing contextually accurate translations without storing your data on external servers, maintaining a privacy-first approach.
What Are Vector Embeddings?
A vector embedding is a numerical representation of an object, such as a word, phrase, document, image, or even an entire concept, as a list of numbers (a vector). Each number in the vector corresponds to a dimension in a multi-dimensional space. The key insight is that the position of an object's vector in this space is not arbitrary; it is learned in such a way that semantically similar objects are mapped to vectors that are close to each other.
Consider words: the word "king" might be represented by a vector, and the word "queen" by another. In a well-trained embedding space, the vector for "king" minus "man" plus "woman" would ideally result in a vector very close to that of "queen." This famous analogy illustrates the ability of embeddings to capture complex relationships and analogies between data points. This transformation from raw data to meaningful numerical vectors is what empowers many modern AI systems.
The Mechanics of Embedding Generation
The process of generating vector embeddings typically involves neural networks. These networks are trained on vast datasets to learn the underlying patterns and relationships within the data. For text, models like Word2Vec, GloVe, or more advanced transformer-based architectures such as BERT or GPT are commonly used. These models analyze the context in which words or phrases appear, learning to predict surrounding words or next words, and in doing so, they implicitly learn a rich, dense representation for each linguistic unit.
For instance, in a skip-gram Word2Vec model, the network is trained to predict context words given a target word. The weights learned in the hidden layer of this neural network, after training, form the vector embedding for each word. Similarly, for images, convolutional neural networks (CNNs) can extract features from different layers, with the output of a specific layer often serving as the image's embedding. The goal is always to distill complex, high-dimensional input into a more compact, semantically rich vector.
Semantic Similarity and Distance Metrics
Once data is transformed into vector embeddings, quantifying the similarity between two items becomes a straightforward mathematical calculation. The most common metric for this is cosine similarity. Cosine similarity measures the cosine of the angle between two vectors in a multi-dimensional space. A cosine similarity close to 1 indicates that the vectors are pointing in roughly the same direction, implying high semantic similarity. A value close to -1 suggests strong dissimilarity, while 0 implies orthogonality (no relation).
Another frequently used metric is Euclidean distance, which measures the straight-line distance between two points in the vector space. While Euclidean distance is intuitive, it can be less effective than cosine similarity in high-dimensional spaces, especially when the magnitude of the vectors varies significantly. For most semantic tasks, cosine similarity is preferred because it focuses on the orientation rather than the magnitude of the vectors, effectively capturing the direction of meaning.
Key Applications Across Industries
Vector embeddings have revolutionized numerous fields, enabling capabilities that were previously challenging or impossible:
Natural Language Processing (NLP): Embeddings are fundamental for tasks like semantic search, where queries retrieve results based on meaning rather than just keyword matching. They power sentiment analysis, text summarization, and named entity recognition. For developers, understanding these embeddings can significantly enhance the performance of content analysis and SEO analysis tools.
Recommendation Systems: By embedding users and items (products, movies, articles) into the same vector space, systems can recommend items whose embeddings are close to a user's preferences or other items they have interacted with.
AI Translation: Embeddings allow translation models to understand the semantic context of words and phrases in one language and find their closest semantic equivalents in another. This goes beyond mere word-for-word substitution, leading to more natural and accurate translations. FreeDevKit's AI Translator tool leverages these principles to provide precise, context-aware translations directly in your browser, ensuring your data remains private.
Image and Audio Processing: Embeddings facilitate content-based image retrieval, facial recognition, and audio classification. For example, an image embedding can be used to find visually similar images in a large database.
Anomaly Detection: Outliers in a dataset often have embeddings that are distant from the clusters of normal data points, making them easier to identify.
Types of Embeddings
The field of embeddings is constantly evolving, with various types tailored to different data and tasks:
Word Embeddings: Early and influential models like Word2Vec and GloVe map individual words to vectors. They capture lexical and semantic relationships between words.
Sentence/Document Embeddings: Models like BERT, Sentence-BERT, or Universal Sentence Encoder generate a single vector for an entire sentence or document. These are crucial for understanding the overall meaning of longer texts. You can read more about the foundational aspects of these representations in our foundational article on vector embeddings.
Image Embeddings: Derived from CNNs, these vectors represent the visual features of an image, enabling tasks like image search and classification.
Multimodal Embeddings: Advanced models like CLIP learn to embed different modalities (e.g., text and images) into a shared space, allowing for cross-modal tasks like searching images using text descriptions.
Implementing Vector Embeddings
For developers, implementing vector embeddings typically involves one of two approaches:
Using Pre-trained Models: This is the most common and often the most practical approach. Major frameworks like TensorFlow and PyTorch offer access to pre-trained models (e.g., BERT, GPT-2, ResNet for images) that have been trained on massive datasets. You can simply load these models and use them to generate embeddings for your specific data. This saves significant computational resources and time.
Fine-tuning or Training Custom Models: For highly specialized domains or when pre-trained models don't perform optimally, you might fine-tune an existing model on your domain-specific data or even train a new embedding model from scratch. This requires substantial data, computational power, and expertise in machine learning.
Once embeddings are generated, they are often stored in specialized vector databases (also known as vector search engines) that are optimized for fast similarity searches across millions or billions of vectors. This infrastructure is critical for real-time applications like semantic search and recommendation engines.
Common Mistakes to Avoid
Working with vector embeddings requires attention to detail to ensure their effectiveness:
Ignoring Data Preprocessing: The quality of your input data directly impacts the quality of your embeddings. For text, proper tokenization, lowercasing, removal of stop words, and handling of special characters are crucial. For images, normalization and resizing are standard. Poorly preprocessed data will lead to noisy and less meaningful embeddings.
Choosing the Wrong Embedding Model: Not all embedding models are suitable for every task. A word embedding model might be excellent for understanding individual word relationships but inadequate for capturing the overall sentiment of a document. Always select a model that aligns with the granularity and nature of your task.
Misinterpreting Dimensionality: While higher dimensions can capture more nuance, they also increase computational complexity and can lead to the "curse of dimensionality," where data points become sparse. There's an optimal dimensionality for each problem; it's not always a case of "more is better."
Overlooking Computational Costs: Generating and storing embeddings, especially for large datasets, can be computationally intensive. Real-time similarity searches also require optimized infrastructure. Plan for these costs, particularly when scaling applications.
Neglecting Privacy Implications: When using third-party embedding services or cloud-based AI, be mindful of data transmission and storage policies. FreeDevKit emphasizes privacy by performing all operations, including AI-driven tasks, directly in your browser, ensuring your data never leaves your device unless explicitly shared by you. This approach is critical for sensitive data and compliance.
Best Practices for Working with Embeddings
To maximize the utility of vector embeddings, consider these best practices:
Evaluate Embeddings Rigorously: Don't assume an embedding model is perfect. Use intrinsic evaluation metrics (e.g., word analogy tasks, correlation with human similarity judgments) and extrinsic metrics (e.g., performance on downstream tasks like classification) to assess their quality.
Understand Model Limitations: Be aware that embeddings, while powerful, can inherit biases present in their training data. They might also struggle with out-of-vocabulary words or highly nuanced, context-dependent meanings.
Prioritize Data Privacy and Security: Especially when dealing with sensitive information, ensure your embedding pipeline adheres to strict data governance policies. Browser-based tools, like those offered by FreeDevKit, provide an inherent advantage in this regard by processing data locally, mitigating risks associated with server-side processing.
Leverage Open-Source Tools and Libraries: The AI community offers a wealth of open-source libraries (e.g., Hugging Face Transformers, Gensim) that simplify the generation and manipulation of embeddings. Familiarize yourself with these resources to streamline your development process.
Stay Updated with Research: The field of embeddings is rapidly advancing. Regularly review new research and model architectures to incorporate the latest improvements into your applications. Resources like Web.dev's machine learning guides can provide practical insights into optimizing web performance for AI-driven features.
Conclusion
Vector embeddings are more than just numerical representations; they are the language through which machines comprehend the semantic richness of our world. By transforming diverse data into a unified, meaningful vector space, they unlock capabilities for advanced AI applications, from highly accurate search engines to intelligent recommendation systems and sophisticated language translation. For developers, understanding and effectively utilizing vector embeddings is no longer optional but a core competency in building next-generation AI-powered solutions.
As you delve deeper into AI and machine learning, remember the power of these foundational concepts. For practical application, explore tools that prioritize both functionality and privacy. FreeDevKit offers a suite of browser-based utilities, including our AI Translator, which leverages advanced AI principles to deliver robust performance while ensuring your data remains on your device. Harness the power of semantic understanding without compromising your privacy.